Base de données orientées Graphe et similarité
Il y a de nos jours énormément de données a traiter (Big Data) avec internet, et pour pouvoir gérer et analyser ces données l'utilisation des bases de données est devenue primordiale. Aujourd'hui, les utilisateurs ne peuvent plus faire directement le choix d'un produit, d’un média...
Pour cela, la plupart des entreprises utilisent des systèmes de recommandations. Ces systèmes de recommandations utilisent des algorithmes qui identifient des utilisateurs similaires et leurs recommandent des éléments susceptibles de les intéresser.
Dans ce projet nous n'allons pas utiliser des bases de données relationnelles (qui sont les bases de données les plus courantes) car contrairement à ce qu'indique leur nom, elles ne sont pas efficaces pour gérer les relations. A l'inverse, les bases de données orientées graphe, qui reprennent la théorie des graphes en utilisant des nœuds et des arcs pour représenter et stocker les données, rendent ces bases de données très efficaces pour traiter les relations. Nous allons utiliser ce type de base de donnée car nous nous intéressons aux liens entre les utilisateurs et les « produits ».
L'objectif final de ce projet va être de créer un système de recommandation de film en utilisant les bases de données orientées graphe et des algorithmes de recherche de similarité. Nous allons également utiliser les bases de données orientées graphe avec des données sur la contamination de la maladie du COVID-19.
Creation de bases de données orienté graphe :
Pour réaliser ce projet, j'ai du créer des bases de données orientées graphe. Pour ce faire, j'ai utilisé le système de gestion de base de données (SGBD) orienté graphe Neo4j. Ce SGBD utilise le langage de requête Cypher qui a la particularité d'être basé sur de l'art ASCII (ASCII Art) pour créer ses requêtes ce qui rend le langage visuel et facile à lire. Pour héberger les bases de données Neo4j , j'ai utilisé l’hébergeur Graphendb.

Apprentissage du langage Cypher
Dans le langage cypher il y a quatre éléments importants pour pouvoir créer une base de données orientée graphe :
- Les Nœuds (Nodes) (Les éléments principaux)
- Les relations (Relationships) (Qui relient les nœuds entre eux)
- Les propriétés (Properties) (Les caractéristiques spécifiques des nœuds et relations)
- Les fonctions permettant de gérer ces objets
Créer des nœuds et des relations
Pour créer des nœuds (et des relations) il faut utiliser la fonction CREATE.
Dans cypher un nœud est composé comme ceci : (nomNoeudRacc:labelNoeud {propriétés})
nomNoeudRacc est un nom du nœud raccourci pour le manipuler plus rapidement et facilement dans les requêtes.
labelNoeud est le nom d'un "type" de nœud.
Les propriétés sont définies comme ceci : {nomParametre:valeurParametre}
Enfin les relations sont créées ainsi : -[:NOMRELATION {propriétés}]->
Voici un exemple de création de nœuds et d'une relation qui les relie ainsi que le résultat obtenu :
// Création des noeuds
CREATE (f:Film {titre:"Jurassic Park"})
CREATE (r:Realisateur {prenom:"Steven", nom:"Spielberg", metier:"Realisateur"})
// Création de la relation
MATCH (r:Realisateur) WHERE r.nom = "Spielberg"
MATCH (f:Film) WHERE f.titre = "Jurassic Park"
CREATE (r)-[rel:REALISE {annee:1993}]->(f)
RETURN r,rel,f //Affiche le resultat

Importer une base de données CSV et mise en place de la base de données
Nous voulons dans ce projet utiliser la base de données de MovieLens qui donne la notation des films par des utilisateurs. Le format de cette base de données est CSV et à un en-tête (header).
Voici un lien qui vous mène vers la base de données sur les utilisateurs : [1]
Pour importer cette base dans Neo4j j'ai utilisé les fonctions suivantes :
LOAD CSV WITH HEADERS FROM "lien de la base de données" AS line
Puis vous pouvez utiliser "line" pour récupérer les données et les utiliser dans vos nœuds, relations ou propriétés.
J'ai créé ainsi des nœuds et des relations sous la forme : (Film)-[DU_GENRE]->(Genre)
Les nœuds films ont en paramètre le nom du film et la date de sortie du film.
Les nœuds Genre ont en paramètre le genre du film (Action, Comédie, Horreur...).
Voici le résultat pour le film Toy Story :

Par la suite j'ai créé des nœuds Utilisateur en relation avec des nœuds Film sous la forme :(Utilisateur)-[:A_VU {note}]->(Film)
Les nœuds Utilisateur ont en paramètre l'id, l'âge, le sexe et le travail de l'utilisateur.
Les relations A_VU ont en paramètre la note que l'utilisateur a mis au film.
Voici le résultat pour Toy Story :

La base de données est prête on peut commencer à créer un système de recommandation.
Utilisation d'algorithmes de recherche de similarité et système de recommandation
Similarité de Jaccard
Une manière de mesurer la similarité entre deux ensembles est de calculer l'indice de Jaccard (également appelé coefficient de Jaccard ou coefficient de communauté).
Pour calculer l'indice de Jaccard on calcule le rapport entre le cardinal (la taille) de l'intersection des ensembles considérés et le cardinal de l'union des ensembles, soit la formule suivante :
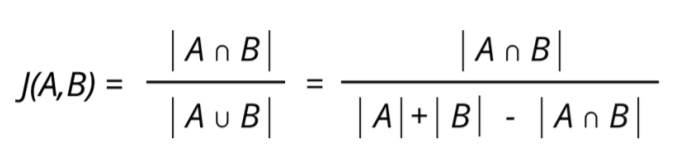
En appliquant cette formule aux films vus par les utilisateurs, je peux regarder les utilisateurs les plus similaires par rapport aux mêmes films qu'ils ont vus.
Pour ceci, j'ai utilisé les commandes suivantes :
MATCH (u1)-[:A_VU]->(f:Film)<-[:A_VU]-(u2) WITH u1, u2, count(distinct f) as inter // inter est le cardinal de u1 inter u2 MATCH (u1)-[:A_VU]->(f:Film) WITH u1, count(distinct f) as nb_u1, u2,inter //nb_u1 est le cardinal de u1 MATCH (u2)-[:A_VU]->(f:Film) WITH u2, count(distinct f) as nb_u2, u1, inter, nb_u1 //nb_u2 est le cardinal de u2 RETURN u1.idUtilisateur, u2.idUtilisateur, inter, nb_u1, nb_u2, inter*1.0/(nb_u1+nb_u2-inter) as jaccard ORDER BY jaccard DESC LIMIT 10
Cependant ma base de données étant "petite" je trouve que les utilisateurs qui se ressemblent le plus sont ceux ayant vu un même unique film.
Pour contrer ce problème j'ai ajouté qu'il fallait que les utilisateurs aient au moins vu 5 films en commun j'ai ajouté la requête suivante : WHERE inter >= 5
Et voici le résultat pour les 10 utilisateurs les plus similaires dans l'ordre décroissant :

Création de liste de recommandation :
Maintenant que j'ai deux utilisateurs similaires je peux trouver des films qui sont susceptibles d’intéresser ces utilisateurs en regardant les films qu'un utilisateur a regardé mais pas l'autre.
Pour obtenir une liste de recommandation pour l'utilisateur avec l'id 117 j'ai filtré les résultats en prenant les films que l'utilisateur 162 à vu mais pas l'utilisateur 117.
Voici la liste de films que je trouve :

Dans l'autre sens je trouve :

Application des bases de données orientées graphes et recherche de similarité sur la contamination du COVID-19
Importation de la base de données sur les patients contaminés et mise en place de la base de données
Pour étudier les données de la base j'ai importé la base de données sous la forme : (Patient)-[:RESIDE]->(Ville)-[:LOCALISE]->(Pays)
Les nœuds Pays et Villes possède l'unique paramètre "nom".
Les nœuds Patient eux ont des paramètres sur l'age, date d’apparition des symptômes, le sexe, si le patient a visité Wuhan, si le patient vient de Wuhan et un id.
On peut voir le résultat suivant en France :

Création de relations de contamination potentielle
J'ai par la suite ajouté des relations de contamination potentielle entre les individus de même ville et si un individu a une date d'apparition des symptômes antérieure à un autre individu.
Pour commencer je ne me suis intéressé qu'aux patients qui possèdent une date de symptôme (qui n'ont pas la date "NA").
Ensuite il fallait trouver un moyen de convertir les chaines de caractères "date", qui sont sous la forme "mois/jour/année", en 3 paramètres jour, mois, année en des entiers pour pouvoir comparer les dates.
Pour ceci j'ai utilisé la fonction split pour supprimer les "/" et les mettre dans une liste.
Puis j'ai utilisé la fonction SET pour créer les nouveaux paramètres.
J'ai utilisé les requêtes suivantes :
MATCH (p:Patient) WHERE p.date_symptome <> "NA" WITH split(p.date_symptome, '/') AS liste,p SET p.mois = toInteger(liste[0]), p.jour = toInteger(liste[1]), p.annee = toInteger(liste[2])
Puis j'ai comparé les personnes venant des mêmes villes et qui ont eu des symptômes avant un autre patient pour créer les relations de contamination potentielle.
Exploitation de la base de données :
Dans les résultats qui suivent j'ai enlevé les nœuds qui n'avaient pas de date de symptôme car ils ne fournissent pas d'information.
Voici le résultat pour la ville de Gansu en Chine :

Voici le résultat pour la Chine entière :

Ensuite j'ai décidé de regarder le nombre de personnes ayant visité Wuhan et vivant a Wuhan parmi les infectés pour voir si il y avait une relation.
J'ai calculé le nombre de personnes ayant visité Wuhan, venant de Wuhan, ne venant pas de Wuhan et le total des individus dans la base de données, je trouve ce résultat :

On remarque que sur les 800 contaminés, 170 personnes ont visité Wuhan et 143 vivaient à Wuhan. Cela nous donne un pourcentage de (313/800)*100 = 39,125% il y a donc plus d'un contaminé sur 3 qui a été à Wuhan.
On peut donc supposer qu'il y a peut être une relation entre le fait d'avoir visité ou vécu a Wuhan et d'être contaminé.
J'ai voulu ensuite regarder d'ou venaient les premiers infectés (de la base de données).
Avec les résultats de requêtes j'ai trouvé que 27 infectés sur 30 ont été à Wuhan parmi ces premiers infectés, ce qui montre bien que l'épidémie a commencé là-bas.
Enfin j'ai voulu voir dans quel ordre de pays s'est propagé le virus.
Voici la liste des Pays que j'ai trouvé par ordre chronologique de contamination à partir de la base de données :

Code source
Vous pouvez voir toutes les requêtes que j'ai utilisé lors de ce projet dans le fichier txt dans le lien GitHub ci-dessous :
https://github.com/TheSummer1502/VISI201.git
Source
Documentation sur le langage Cypher
https://neo4j.com/docs/cypher-manual/4.0/
Pages sur les bases de données :
Pour les bases de données relationelles
https://fr.wikipedia.org/wiki/Base_de_donn%C3%A9es_relationnelle
Pour les bases de données orientées graphe
https://fr.wikipedia.org/wiki/Base_de_donn%C3%A9es_orient%C3%A9e_graphe
Fonctionnement de la similarité de Jaccard :
https://fr.wikipedia.org/wiki/Indice_et_distance_de_Jaccard
Site de Neo4j :
https://neo4j.com/
Site de Graphendb :
https://www.graphenedb.com/
Conclusion
A travers ce projet j'ai pu découvrir en général l'univers des bases de données que je ne connaissais pas auparavant, et voir l'importance qu'elles ont dans le monde actuel. Lors de ce projet j'ai vu plus en détail les bases de données orientées graphe. J'ai pu voir qu'elles offraient beaucoup plus d'avantages lors de la manipulation de relations par rapport aux bases de données relationnelles.
J'ai appris à me servir du langage Cypher pour manipuler les bases de données avec le système de gestion de bases de données Neo4j. J'ai trouvé ce langage assez simple à apprendre car le format en ASCII Art le rend très visuel et facile à comprendre.
De plus j'ai beaucoup aimé le fait que l'on puisse observer facilement les résultats de nos manipulations avec l'affichage des bases de données sous forme de graphes.
Egalement j'ai appris différentes manières de calculer la similarité entre des éléments notamment avec l'indice de Jaccard mais j'ai également découvert d'autres moyens de la calculer comme la similarité cosinus, cependant je n'ai pas réussi à l'appliquer.
J'ai également découvert que la plupart des bases de données ne sont pas parfaites et possèdent des données manquantes ou erronées. Pour ceci, il faut fournir un travail supplémentaire pour pouvoir quand même exploiter des résultats malgré les données lacunaires.
Au final, j'ai trouvé ce projet très enrichissant et intéressant, j'ai pu voir une partie de toutes les possibilités qu'offrait ce type de base de données et me rendre compte que savoir les manipuler à haut niveau peut réellement apporter de nouvelles perspectives pour la recherche.