Tables de hachage et dictionnaires
Les tables de hachages sont des tableaux dynamiques permettant de créer une association clé-valeur pour une effectuer des insertions, suppressions et recherches rapides.
Les codes proposés ici pour les tables et fonctions de hachages sont écrits en langage Python. Les dictionnaires Python sont également basés sur le principe des tables de hachage et serviront d’outil de comparaison.
Définitions
- Table de hachage : tableau associatif permettant de créer une association clé-valeur. Chaque couple (clé-valeur) se voit attribuer une position dans la table à l’aide de la valeur de hachage de la clé. Cette valeur de hachage est à partir de la clé via une fonction de hachage. Cette position dépend de la taille de la table ainsi que de la clé. La recherche ou modification d’une valeur, la suppression ou l’ajout d’un couple s’effectuent à l’aide de la clé, elle apparaît donc de façon unique dans la table. Enfin, la recherche, insertion et suppression d'un élément ont toutes un temps de calculs rapide.
- Fonction de Hachage : fonction prenant en paramètre un élément immuable et de taille non prédéfinie et renvoyant un entier de taille prédéfinie. Le calcul de la fonction doit être rapide.
Fonction de Hachage
Première approche des fonctions de hachage

En Python, une fonction de hachage peut prendre en paramètre des chaines de caractères, un entier, un flottant ou encore un tuple, c'est-à-dire des éléments "hachables". Le but est de transformer cet élément en un nombre entier de taille définie pour ensuite, via un modulo de la taille de la table, qu’il devienne un indice correspondant à une position dans la table de hachage.
Réduire des éléments de taille non définie en entier de taille définie risque de causer des collisions, c’est-à-dire qu’au moins deux éléments obtiennent la même position. Or selon le format des tables, ces éléments ne peuvent pas occuper la même case (voir adressage ouvert). Ce problème est inévitable lorsque les ajouts d’éléments ne sont pas prédictibles. Le mieux est donc de limiter le nombre de collisions. Pour cela, il faut bien construire la fonction de hachage.
Par exemple la fonction ci-contre n’est pas une bonne fonction de hachage car :
- La table de hachage apparait dans la fonction, or la fonction de hachage doit en être indépendante.
- Le ‘else’ permet d’associer un entier à une chaine de caractère : l’indice est la somme de chaque caractère de la chaine transformée en son numéro ASCII puis multipliée par sa position dans la chaine. Ainsi, chacun des premiers caractères des chaines ne sont pas pris en compte dans la somme (multiplication par 0) donc les chaines d’un caractère ont toutes pour indice 0 de la même façon, ‘mot’, ‘lot’, ‘got’ ont le même indice, etc…
- Pour ce qui est des entiers, tous les nombres entiers multiples de la taille de la table auront le même indice. La répartition des positions n’est pas suffisamment homogène.
Un autre exemple de fonction à éviter, est une fonction qui effectue une multiplication par un entier pair. Les cases occupées de la table se limiteraient alors aux indices pairs.
Ainsi, il est recommandé d’effectuer une multiplication par un grand nombre premier pour améliorer la répartition lors du modulo étant donné que les propriétés des nombres premiers sont utilisées. De la même façon, il est bien que le modulo final soit un nombre premier. Enfin, la réduction de l’indice à une position de la table se fera directement dans les méthodes de la table.
Différents types de fonctions

De nombreuses fonctions de hachage ont été imaginées pour répondre au mieux aux critères de répartition et de calcul.
Hachage multiplicatif
Le hachage multiplicatif consiste à prendre une clé m et la multiplier par une constante. Le modulo 1 conserve la partie fractionnaire seulement. Ce résultat est à nouveau multiplié par une puissance de 2 ce qui facilite les calculs pour l’ordinateur qui fonctionne avec des bits. En effet, une multiplication par n = 2p représente donc simplement un décalage p vers la droite. L’indice renvoyé est la partie entière de ce nombre.
Formule : Échec de l’analyse (SVG (MathML peut être activé via une extension du navigateur) : réponse non valide(« Math extension cannot connect to Restbase. ») du serveur « https://wikimedia.org/api/rest_v1/ » :): {\displaystyle hash(m) = floor({n}\times{(({m}\times{c}) mod 1)})} Avec m la clé, c une constante et n une puissance de 2.
Hachage de Fibonacci
Le hachage de Fibonacci est une variante du hachage multiplicatif. La constante c du hachage multiplicatif est à présent : Échec de l’analyse (SVG (MathML peut être activé via une extension du navigateur) : réponse non valide(« Math extension cannot connect to Restbase. ») du serveur « https://wikimedia.org/api/rest_v1/ » :): {\displaystyle \dfrac{2^t}{\phi}} avec t la taille de la clé et φ le nombre d’or : Échec de l’analyse (SVG (MathML peut être activé via une extension du navigateur) : réponse non valide(« Math extension cannot connect to Restbase. ») du serveur « https://wikimedia.org/api/rest_v1/ » :): {\displaystyle \dfrac{1+ \sqrt 5}{2}} . Cette fonction renvoie des indices de manière uniforme sur l’ensemble de la table.
Fonction de hachage parfaite
Les fonctions précédentes limitent les collisions mais celles-ci sont toujours possible. La fonction de hachage parfaite a pour but de renvoyer de manière unique une valeur de hachage pour chaque clé. Il est possible d’en créer une lorsque les clés sont connues et que celles-ci ne risquent pas de changer. Pour les autres cas, une telle fonction est difficile à trouver en un temps de calcul raisonnable.
Table de Hachage et optimisation
Les tables de hachage s’implémentent comme de simples tableaux de listes avec certaines propriétés. Il est possible de les initialiser avec la taille voulue. Voici deux formats possibles d'implémentation des tableaux :
| Hash 1 | Hash 2 |
|---|---|
| Tableau contenant une liste de tableaux | Tableau contenant une liste de valeurs par défaut (None) |


Changement de taille de la table
La taille prédéfinie ne reste pas telle quelle selon les actions effectuées par l’utilisateur, on dit que ce sont des tableaux dynamiques.
Espace libre et ajout d’un élément
Les tables de hachage sont initialisées comme étant vide aux yeux de l’utilisateur. En réalité, la table possède déjà une taille positive non nulle. Dans les exemples ci-dessus, il est possible de choisir la taille initiale.
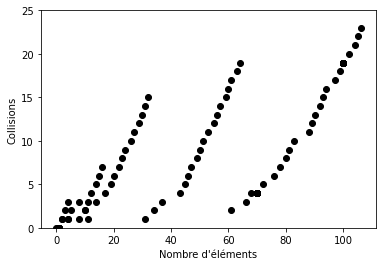
Taux d’agrandissement : 2
Espace vide : 1%
On remarque que le nombre de collisions est élevé par rapport au nombre d’éléments.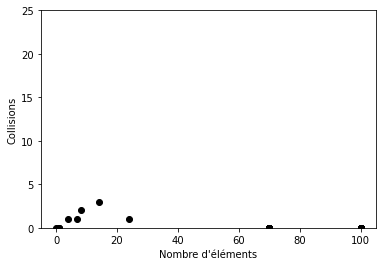
Taux d’agrandissement : 3
Espace vide : 50%
Le nombre de collisions est très faible voire nul lorsque le nombre d’éléments est supérieur à 25.


Il sera par moment nécessaire d’agrandir la table lorsqu’elle n’a plus de case vide (cf. Hash2) mais que l’insertion d’éléments n’est pas terminée, et pour limiter le nombre de collisions. En effet, il est possible qu'une table ne soit jamais complètement remplie à cause des possibles collisions (cf. Hash1). Ainsi, il est préférable de prévoir une marge de mémoire vide.
Par exemple, une table initialisée à une taille de 4, avec une marge de 50% d’espace vide s’agrandira à l’ajout d’un troisième élément. Cette opération met en jeu deux paramètres : le pourcentage de mémoire vide et le taux d’agrandissement.
Tests complémentaires en Annexe.
Après plusieurs tests en faisant varier la marge et l’augmentation de la taille, doubler la capacité de la table lorsque les deux tiers de sa taille sont occupés, est un compromis d’optimisation raisonnable. L’espace vide n’est pas gaspillé de manière excessive et le nombre de collisions n’est pas trop élevé.
Lors de l'ajout d'un élément il faudra parcourir la table afin de respecter l'unicité de la clé. Si celle-ci est déjà présente dans la table, alors seule la valeur associée sera mise à jour, sinon il faut ajouter le couple à la table en suivant la méthode de gestion de collisions utilisé.
Suppression d’un élément
De la même façon que l’ajout d’un élément, la suppression s’effectue à partir de la clé donnée par l’utilisateur. La valeur de hachage est calculée et la complexité de la recherche est de Échec de l’analyse (SVG (MathML peut être activé via une extension du navigateur) : réponse non valide(« Math extension cannot connect to Restbase. ») du serveur « https://wikimedia.org/api/rest_v1/ » :): {\displaystyle O(1)} dans le meilleur des cas.
Lorsque l’élément est le seul à se trouver à l’emplacement indiqué, il n’y a pas de collision détectée au niveau de ce couple, dans le cas de hash 1, l’élément est supprimé du tableau pour retrouver un tableau vide. Dans le cas de hash 2, deux possibilités :
- Mettre une nouvelle valeur par défaut, par exemple -1,
- Mettre la valeur par défaut initiale : None.

Cas du -1 :
Lorsque le couple à supprimer est trouvé, il est remplacé par la valeur « -1 ». Pour une recherche plus efficace, dès que le taux défini de « -1 » est atteint, il faut parcourir la table afin de retirer et replacer les éléments suivant leur valeur de hachage.
En effet lorsque deux éléments sont en collisions, dans le cas de hash2, on insère l’élément dans la case vide suivante. Si le premier élément est supprimé, celui avec qui il était en collision doit récupérer sa place.
Cas du None :
A chaque suppression, l’élément est remplacé par sa valeur par défaut initiale : None. Puis, si une collision a été supprimée, alors les éléments dans la table sont replacés.
S’il est prévu un grand nombre d’insertions puis un grand nombre de suppressions, il peut être intéressant de réduire la taille de la table. Cependant si les insertions et suppressions sont nombreuses et répétitives, il est préférable de conserver la taille de la table lors du dernier agrandissement afin d’avoir un temps de calcul raisonnable.
Gestion des collisions
Adressage fermé
L’adressage fermé consiste à créer une chaine d’éléments de façon externe à la table. Pour le cas de Hash1, la table de hachage est un tableau de tableaux, ainsi il est possible d’insérer plusieurs couples au sein de chacun des sous-tableaux.
Pour rechercher la valeur associée à une clé, il faut :
- Calculer la valeur de hachage de la clé
- Réduire cette valeur pour obtenir un indice
- Effectuer un accès au sous-tableau se trouvant à l'indice obtenu, calcul de complexité Échec de l’analyse (SVG (MathML peut être activé via une extension du navigateur) : réponse non valide(« Math extension cannot connect to Restbase. ») du serveur « https://wikimedia.org/api/rest_v1/ » :): {\displaystyle O(1)}
- Parcourir le sous-tableau de façon linéaire afin de comparer la clé demandée avec celles présentes dans le sous-tableau, calcul de complexité Échec de l’analyse (SVG (MathML peut être activé via une extension du navigateur) : réponse non valide(« Math extension cannot connect to Restbase. ») du serveur « https://wikimedia.org/api/rest_v1/ » :): {\displaystyle O(m)} avec m la taille du sous-tableau
- Récupérer la valeur et la renvoyer
Pour insérer un couple, il faut effectuer les mêmes quatre premières étapes de la recherche, si la clé n'est pas présente alors il suffit d'insérer le nouveau couple dans le sous-tableau, sinon il suffit de mettre à jour la valeur.
Pour la suppression d'un couple, il faut effectuer les mêmes quatre premières étapes de la recherche, si la clé n'est pas présente alors l'état de la table reste inchangé. Dans le cas contraire, il faut retirer le couple de la liste en décalant les éléments qui le suivent.
Adressage ouvert
Lors de collisions, avec une table comme Hash2, il est possible de placer l’élément en collision dans une autre que case que celle indiquée par la position.
- Adressage ouvert linéaire : l’insertion s’effectue dans la prochaine case vide en parcourant la table via l'addition d'une constante entière, par exemple 1.
- Adressage ouvert quadratique : le parcours des cases se fait de manière quadratique.
La formule est position = (hash(k) + f(x)) mod t, avec hash() la fonction de hachage, k la clé, f(x) une fonction et t la taille de la table.
Par exemple :
Soit f(x) = x2 + 3x.
Une table de hachage :

Pour insérer Cle4 : valeur4 dont la valeur de hachage est 0, la case est déjà occupée. Par la fonction f, f(0)=0, la case est déjà occupée, il faut donc poursuivre : f(1) = 1 + 3*1 = 4. Position = (hash(cle4) + f(1)) mod t, avec t la taille de la table.
La case d’indice 4 de la table est libre, cle4 : valeur4 peut être inséré dans cette case.
Double Hachage
Le double hachage (double hashing) consiste à créer deux fonctions de hachage indépendantes. La valeur de hachage d’une clé est calculée par les deux fonctions puis, le couple sera placé où il y a le moins de collisions parmi les deux propositions. Cette version permet en théorie de réduire la taille des listes de collisions. Cette méthode est souvent combinée à l'adressage fermé afin de réduire la taille des sous-tableaux.
Recherche d’un élément
Le but est de renvoyer la valeur associée à une clé donnée lorsque celle-ci existe. Pour retrouver le couple, il suffit de calculer la valeur de hachage de la clé. L’accès d’un élément dans un tableau à partir d’un indice a une complexité de . Comme il est possible que l’élément recherché ne soit pas à l’indice indiqué par la fonction de hachage, il est important de comparer les clés.
Dans le cas de Hash1, si la clé du premier élément du tableau n’est pas la bonne, alors il faut parcourir ce sous-tableau, la complexité dans le pire des cas est alors de O(n) avec n la taille du sous-tableau.
Dans le cas de l’utilisation du double hachage avec Hash1 par exemple, les sous-tableaux à parcourir seront plus petits, pratiquement de moitié de taille qu’avec l’utilisation d’une seule fonction de hachage.
Dans le cas de Hash2, si la clé n’est pas à l’emplacement indiqué, il faut alors parcourir la table en appliquant la même méthode que pour la gestion des collisions utilisée au moment de l’ajout d’élément.
Dans les trois cas, l’élément de comparaison est la plus grande chaine de collisions possibles. Plus cette chaine est grande et plus la recherche d’un élément prendra du temps.

Les tests
Grand nombre d'insertions
En informatique, les tests ont une grande importance. Comme vu précédemment, ils peuvent permettre de prendre une décision quant au choix des valeurs des paramètres, ils permettent également de vérifier le bon fonctionnement du code, des différentes fonctions, etc…
Il faut donc vérifier que chacune des méthodes associées aux tables de hachages fonctionnent individuellement, puis qu’il n’y a pas d’incohérence lors de l’utilisation globale. De la même façon les fonctions de hachage peuvent être testées indépendamment des tables.
Les tables de hachage permettent de gérer un grand nombre de données. Il est possible de tester les capacités des tables en parcourant un fichier et répertoriant le nombre d’occurrences de chaque caractère ou chaine de caractères rencontrés dans le fichier. Le retour de cette table peut être conséquent : pour vérifier qu’aucun élément n’a été oublié, il faut effectuer la même opération avec les outils proposés par l’éditeur de code. Ici, les dictionnaires python servent de références. Il ne reste plus qu’à comparer les éléments de chacun.
Invariants de boucles
Ce sont des propriétés qui restent vraies à n’importe quel moment de la boucle. Par exemple pour compter le nombre d’occurrences de chaque caractère dans un texte, il est possible de créer un invariant de boucle qui vérifie si le nombre d’éléments inséré dans la table correspond au nombre d’éléments différents relevés.
En python, les invariants de boucles peuvent se traduire par l’utilisation d' "assert" qui permet d’arrêter l’exécution du programme dès qu’une propriété n’est pas vérifiée.
Améliorations pour l'utilisateur
Raccourcis utilisateur
Pour effectuer une action sur une table, il est nécessaire d’appeler une méthode. En python, lors de l’utilisation des dictionnaires, il existe plusieurs raccourcis pour l’insertion, suppression et recherche d’un élément. Il est possible de redéfinir ces raccourcis pour qu’ils correspondent à une des méthodes des tables de hachage en renvoyant vers les méthodes décrites précédemment.
Raccourcis possibles :
| Fonctionnalité | Python | Utilisation |
|---|---|---|
| Ajouter un couple | __setitem__ | table[clé] = valeur |
| Supprimer un couple | __delitem__ | del table[clé] |
| Recherche un couple | __getitem__ | table[clé] |
Affichage ressemblant au dictionnaire python

Pour un affichage de la table plus lisible et ressemblant à celui des dictionnaires Python, il faut redéfinir la fonction __str__ . Pour cela, il suffit de parcourir les éléments de la table et définir la façon de les afficher et de les organiser.
Annexes
Tableaux des tests de gestion d’ajout d’éléments
| Espace vide \ Agrandissement de la table | 2 | 3 | 4 |
|---|---|---|---|
| 1% | |||
| 33.33% | |||
| 50% |









{kind=link}
Code Python
Fichier:Hash Table version 1.pdf
Fichier:Hash Table version 2.pdf
Fichier:Hash Table version 3.pdf