« Base de données orientées Graphe et similarité » : différence entre les versions
Aucun résumé des modifications |
Aucun résumé des modifications |
||
| Ligne 21 : | Ligne 21 : | ||
Pour créer des noeuds (et des relations) il faut utiliser la fonction CREATE. <br/> |
Pour créer des noeuds (et des relations) il faut utiliser la fonction CREATE. <br/> |
||
Dans cypher un noeud est composé comme ceci : <br/> |
Dans cypher un noeud est composé comme ceci : <br/> |
||
<code>(nomNoeudRacc:labelNoeud {propriétés})</code> |
|||
<br/> |
<br/> |
||
nomNoeudRacc est un nom du noeuds raccourci pour le manipuler plus rapidement et facilement dans les requêtes.<br/> |
nomNoeudRacc est un nom du noeuds raccourci pour le manipuler plus rapidement et facilement dans les requêtes.<br/> |
||
| Ligne 27 : | Ligne 27 : | ||
<br/><br/> |
<br/><br/> |
||
Les propriétés sont définis comme ceci : |
Les propriétés sont définis comme ceci : |
||
<code>{nomParametre:valeurParametre}</code> |
|||
<br/><br/> |
<br/><br/> |
||
Enfin les relations sont crées ainsi : |
Enfin les relations sont crées ainsi : |
||
<code>-[:NOMRELATION {propriétés}]-></code> |
|||
<br/><br/> |
<br/><br/> |
||
Voici un exemple de création de noeuds et d'une relation qui les relient ainsi que le resultat obtenu : |
Voici un exemple de création de noeuds et d'une relation qui les relient ainsi que le resultat obtenu : |
||
| Ligne 49 : | Ligne 49 : | ||
Voici un lien qui vous mène vers la base de donnée sur les utilisateurs : [https://www.dropbox.com/s/piz58gre87s9miu/u.user.csv?] <br/> |
Voici un lien qui vous mène vers la base de donnée sur les utilisateurs : [https://www.dropbox.com/s/piz58gre87s9miu/u.user.csv?] <br/> |
||
Pour importer cette base dans Neo4j j'ai utilisé les fonctions suivantes : <br/> |
Pour importer cette base dans Neo4j j'ai utilisé les fonctions suivantes : <br/> |
||
<code>LOAD CSV WITH HEADERS FROM "lien de la base de donnée" AS line</code> |
|||
<br/> |
<br/> |
||
Puis vous pouvez utiliser "line" pour récupérer les données et les utiliser dans vos noeuds, relations ou propriété. |
Puis vous pouvez utiliser "line" pour récupérer les données et les utiliser dans vos noeuds, relations ou propriété. |
||
<br/><br/> |
<br/><br/> |
||
J'ai crée ainsi des noeuds et des relations sous la forme : <br/> |
J'ai crée ainsi des noeuds et des relations sous la forme : <br/> |
||
<code>(Film)-[DU_GENRE]->(Genre)</code> |
|||
<br/> |
<br/> |
||
Les noeuds films ont en paramètre le nom du film et la date de sortie du film. <br/> |
Les noeuds films ont en paramètre le nom du film et la date de sortie du film. <br/> |
||
| Ligne 61 : | Ligne 61 : | ||
[[Fichier:Exemple_genre.png | center]] <br/> |
[[Fichier:Exemple_genre.png | center]] <br/> |
||
Par la suite j'ai crée des noeuds Utilisateur en relation avec des noeuds Film sous la forme : <br/> |
Par la suite j'ai crée des noeuds Utilisateur en relation avec des noeuds Film sous la forme : <br/> |
||
<code>(Utilisateur)-[:A_VU {note}]->(Film)</code> |
|||
Les noeuds Utilisateur ont en paramètre l'id, l'âge, le sexe et le travail de l'utilisateur.<br/> |
Les noeuds Utilisateur ont en paramètre l'id, l'âge, le sexe et le travail de l'utilisateur.<br/> |
||
Les relations A_VU ont en paramètre la note que l'utilisateur a mit au film.<br/> |
Les relations A_VU ont en paramètre la note que l'utilisateur a mit au film.<br/> |
||
| Ligne 90 : | Ligne 90 : | ||
Cependant ma base de donnée étant "petite" je trouve que les utilisateurs qui se ressemblent le plus sont ceux ayant vu un même unique film. <br/> |
Cependant ma base de donnée étant "petite" je trouve que les utilisateurs qui se ressemblent le plus sont ceux ayant vu un même unique film. <br/> |
||
Pour contrer ce problème j'ai ajouter qu'il fallait que les utilisateurs aient au moins vu 5 films en commun j'ai ajouter la requêtes suivante : |
Pour contrer ce problème j'ai ajouter qu'il fallait que les utilisateurs aient au moins vu 5 films en commun j'ai ajouter la requêtes suivante : |
||
<code>WHERE inter >= 5</code> |
|||
<br/> |
<br/> |
||
Et voici le resultat pour les 10 utilisateur les plus similaires dans l'ordre décroissant : <br/> |
Et voici le resultat pour les 10 utilisateur les plus similaires dans l'ordre décroissant : <br/> |
||
| Ligne 110 : | Ligne 110 : | ||
== Application des bases de données orienté graphes et recherche de similarité sur la contamination du COVID-19 == |
== Application des bases de données orienté graphes et recherche de similarité sur la contamination du COVID-19 == |
||
=== Importation de la base de donnée sur les patients contaminés et mise en place de la base de donnée === |
|||
Pour étudier les données de la base j'ai importer la base de donnée sous la forme : <br/> |
|||
<code>(Patient)-[:RESIDE]->(Ville)-[:LOCALISE]->(Pays)</code> |
|||
Version du 17 mai 2020 à 10:53
Il y a de nos jours énormément de données a traiter (Big Data) avec internet, et pour pouvoir gérer et analyser ces données l'utilisation des bases de données est devenu primordial. De nos jours, les utilisateurs ne peuvent plus faire directement le choix d'un produit, d’un média...
Pour cela, la plupart des entreprises utilisent un système de recommandations. Ces systèmes de recommandations utilisent des algorithmes qui identifie des utilisateurs similaires et leurs recommande des éléments susceptible de les intéresser.
Dans ce projet nous n'allons pas utiliser des bases de données relationnels (qui sont les bases de données les plus courantes) car contrairement à ce qu'indique leur nom, elles ne sont pas efficaces pour gérer les relations. A l'inverse, les bases de données orientés graphe, qui reprennent la théorie des graphes en utilisant de noeuds et des arcs pour représenter et stocker les données, rends ces bases de données très efficace pour traiter les relations. Nous allons utiliser ce type de base de donnée car nous nous intéressons au liens entre les utilisateur et les « produits ».
L'objectif final de ce projet va être de créer un système de recommandation de film en utilisant les bases de données orienté graphes et des algorithmes de recherche de similarité. Nous allons également faire une application des bases de données orienté graphe avec des données sur la contamination de la maladie du COVID-19.
Creation de bases de données orienté graphe :
Pour réaliser ce projet, j'ai du créer des bases de données orientées graphe. Pour ce faire, j'ai utilisé le système de gestion de base de données (SGBD) orienté graphe Neo4j. Ce SGBD utilise le langage de requête Cypher qui a la particularité d'être basé sur de l'art ASCII (ASCII Art) pour créer ces requêtes ce qui rends le langage visuel et facile à lire. Pour héberger les bases de données Neo4j , j'ai utilisé l’hébergeur Graphendb.

Apprentissage du langage Cypher
Dans le langage cypher il y a quatre éléments important pour pouvoir créer une base de données orienté graphe :
- Les Noeuds (Nodes) (Les principales instances)
- Les relations (Relationships) (Qui relient les noeuds entre eux)
- Les propriétés (Properties) (Les caractéristique spécifique des noeuds et relations)
- Les fonction permettant de gérer ces objets
Créer des noeuds et des relations
Pour créer des noeuds (et des relations) il faut utiliser la fonction CREATE.
Dans cypher un noeud est composé comme ceci :
(nomNoeudRacc:labelNoeud {propriétés})
nomNoeudRacc est un nom du noeuds raccourci pour le manipuler plus rapidement et facilement dans les requêtes.
labelNoeud est le nom d'un "type" de noeud.
Les propriétés sont définis comme ceci :
{nomParametre:valeurParametre}
Enfin les relations sont crées ainsi :
-[:NOMRELATION {propriétés}]->
Voici un exemple de création de noeuds et d'une relation qui les relient ainsi que le resultat obtenu :
// Création des noeuds
CREATE (f:Film {titre:"Jurassic Park"})
CREATE (r:Realisateur {prenom:"Steven", nom:"Spielberg", metier:"Realisateur"})
// Création de la relation
MATCH (r:Realisateur) WHERE r.nom = "Spielberg"
MATCH (f:Film) WHERE f.titre = "Jurassic Park"
CREATE (r)-[rel:REALISE {annee:1993}]->(f)
RETURN r,rel,f //Affiche le resultat

Importer une base de donnée CSV et mise en place de la base de donnée
Nous voulons dans ce projet utiliser la base de donnée de MovieLens qui donne la notions de films par des utilisateurs. Le format de cette base de donnée est CSV et à une en-tête (header).
Voici un lien qui vous mène vers la base de donnée sur les utilisateurs : [1]
Pour importer cette base dans Neo4j j'ai utilisé les fonctions suivantes :
LOAD CSV WITH HEADERS FROM "lien de la base de donnée" AS line
Puis vous pouvez utiliser "line" pour récupérer les données et les utiliser dans vos noeuds, relations ou propriété.
J'ai crée ainsi des noeuds et des relations sous la forme :
(Film)-[DU_GENRE]->(Genre)
Les noeuds films ont en paramètre le nom du film et la date de sortie du film.
Les noeuds Genre ont en paramêtre le genre du film (Action, Comedie, Horreur...).
Voici le résultat pour le film Toy Story :

Par la suite j'ai crée des noeuds Utilisateur en relation avec des noeuds Film sous la forme :
(Utilisateur)-[:A_VU {note}]->(Film)
Les noeuds Utilisateur ont en paramètre l'id, l'âge, le sexe et le travail de l'utilisateur.
Les relations A_VU ont en paramètre la note que l'utilisateur a mit au film.
Voici le résultat pour Toy Story :

La base de données est prête on peux commencer à créer un système de recommandation.
Utilisation d'algorithmes de recherche de similarité et système de recommandation
Similarité de Jaccard
Une manière de mesurer la similarité entre deux ensemble est de calculer l'indice de Jaccard (également appelé coefficient de Jaccard ou coefficient de communauté).
Pour calculer l'indice de Jaccard on calcule le rapport entre le cardinal (la taille) de l'intersection des ensembles considérés et le cardinal de l'union des ensembles, soit la formule suivante :
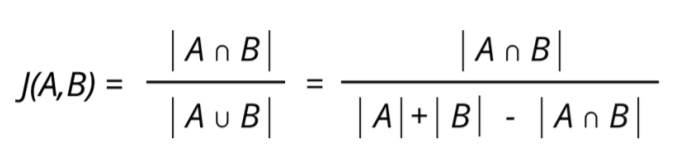
En appliquant cette formule aux films vu par les utilisateur, je peux regarder les utilisateurs les plus similaire par rapport au même films qu'ils ont vu.
Pour ceci, j'ai utilisé les commandes suivantes :
MATCH (u1)-[:A_VU]->(f:Film)<-[:A_VU]-(u2) WITH u1, u2, count(distinct f) as inter // inter est le cardinal de u1 inter u2 MATCH (u1)-[:A_VU]->(f:Film) WITH u1, count(distinct f) as nb_u1, u2,inter //nb_u1 est le cardinal de u1 MATCH (u2)-[:A_VU]->(f:Film) WITH u2, count(distinct f) as nb_u2, u1, inter, nb_u1 //nb_u2 est le cardinal de u2 RETURN u1.idUtilisateur, u2.idUtilisateur, inter, nb_u1, nb_u2, inter*1.0/(nb_u1+nb_u2-inter) as jaccard ORDER BY jaccard DESC LIMIT 10
Cependant ma base de donnée étant "petite" je trouve que les utilisateurs qui se ressemblent le plus sont ceux ayant vu un même unique film.
Pour contrer ce problème j'ai ajouter qu'il fallait que les utilisateurs aient au moins vu 5 films en commun j'ai ajouter la requêtes suivante :
WHERE inter >= 5
Et voici le resultat pour les 10 utilisateur les plus similaires dans l'ordre décroissant :

Création de liste de recommandation :
Maintenant que j'ai deux utilisateurs similaires je peux trouver des films qui sont susceptible d’intéresser ces utilisateurs en regardant les films qu'un utilisateur a regardé mais pas l'autre.
Pour obtenir une liste de recommandation pour l'utilisateur avec l'id 117 j'ai filtrer les résultats en prenant les films que l'utilisateur 162 à vu mais pas l'utilisateur 117.
Voici la liste de films que je trouve :

Dans l'autre sens je trouve :

Application des bases de données orienté graphes et recherche de similarité sur la contamination du COVID-19
Importation de la base de donnée sur les patients contaminés et mise en place de la base de donnée
Pour étudier les données de la base j'ai importer la base de donnée sous la forme :
(Patient)-[:RESIDE]->(Ville)-[:LOCALISE]->(Pays)