Le bytecode Python
Etudiants : MARZIN Simon et PERIVOLAS Baptiste
Chercheur : HYVERNAT Pierre
Introduction
Python est un langage de programmation multiparadigme (à la fois impératif, fonctionnel et orienté objet) créé en 1991. A la difference des langages compilés comme le C, le C++ ou le Rust, le python lui est un langage interprété (nous verrons la différence juste après). Il a la particularité dans son execution, de transformer le code en un code intermédiaire simplifié appelé Bytecode. Ce projet porte sur l'étude du fonctionnement d'un interprèteur python, et plus particulièrement du Bytecode.
Langage compilé VS interprété
Un langage compilé est un langage qui necessite de passer par un compilateur (un programme qui transforme un code source en un code objet) pour transformer le code de base en instructions de bas niveau proche de l'assembleur éxecutable par la machine. En C par exemple, on doit compiler un programme C pour le transformer en .exe avant de pouvoir le lancer. Le compilateur analyse syntaxiquement tout le code, puis le transforme, ce qui fait que les erreurs sont detectées plus tôt. Les langages compilés ont la particularité d'être très rapides et performants, un programme déjà compilé étant très facilement executable. Néanmoins, celà rend le débug ainsi que les test plus complexes.
Un langage interprété a lui besoin d'un interpréteur (ou interprète) pour fonctionner. Il récupère un code source, le traîte, le transforme et l'execute dirrectement dans une machine virtuelle. Les langages interprétés sont donc par conséquent plus lents que les langages compilés, mais il permettent une plus grande flexibilité. La plupart des interpreteurs traîtent et executent le code instruction par instruction. Or, ce n'est pas totalement le cas de l'interprèteur python.
Spécificité de Python
L'interpréteur python a un fonctionnement bien particulier. En effet, il est un hybride entre interprète et compilateur.
Le code source python est d'abord analysé syntaxiquement et cémantiquement en entiereté par un lexer et un parser (expliqué plus en détails plus bas), puis est compilé en code objet intermédiaire, le bytecode. Ce bytecode est ensuite executé instruction par instruction par la machine virtuelle python.
La syntaxe du bytecode est plutôt claire et s'apparente à de l'assembleur siplifié. Chaque instructions du code source python (affectation, calcul, definition de fonction ...) a sa propre représentation bien précise en bytecode.
Voici un exemple de bytecode pour l'instruction a = 10 :
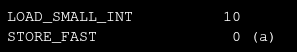

Description du projet
Dans le cadre de nos recherches sur le sujet, nous avons décidé pour comprendre comment fonctionne l'interprèteur python d'en recoder une version simplifiée. Le code que nous avons réalisé prend en entrée un code source python basique, le transforme en code intermédiaire inspiré du vrai bytecode de Python3, et l'execute dans une machine virtuelle. Nous avons donc trouvé pertinnent de découper ce projet en deux parties distinctes : la partie Compilation et la partie Machine virtuelle et execution
Ce code prend en compte quelques fonctionnalités de base de python telles que :
- L'affectation de variable
- Les opérations de base
- La gestion des boucles
- La gestion des conditions
- La définition de fonctions en prenant en compte :
- Les variables locales
- Les variables globales
- Les clotures (ou closures)
- La gestion d'une fonction built-in : print()
Pour ce qui est de l'aspect technique, ce projet a été entièrement développé en python, dans le paradigme de programmation orientée objet (POO).
Partie compilation
Lexer
...
Parser
...
Arbre de syntaxe et compilation
...
Partie machine virtuelle
Comme énoncé précédemment, la macine virtuelle de l'interprèteur python prend en entrée du bytecode, et l'execute.
Fonctionnement global
La machine virtuelle est basée sur une structure de pile Last In First Out (FIFO) pour les instructions. Elle utilise 2 piles différentes, qui ont chacune un rôle bien défini :
- Data stack : La pile où python stocke toutes les données avec lesquelles il travaille, comme les variables, les fonctions etc... (c'est la pile utilisée par la plupart des fonctions)
- Block stack : Utilisée dans les exception, ou pour certaines fonctions.
Dans le cadre de notre projet, nous avons choisi de fonctionner avec une seule pile pour simplifier son fonctionnement.
Notre VM (Virtual Machine) possède donc une pile nomée 'call stack' (ou pile d'execution) qui est utilisée pour à la fois stocker les données, mais également les frames des fonctions (notion qui sera expliquée plus bas).
La VM prend en entrée une liste d'instructions bytecode, d'une classe bytecode que nous avons décidé de créer. Elle execute ensuite instruction par instruction jusqu'à arriver à la fin du programme.
La classe bytecode et la classe Frame
Classe bytecode
Les objets bytecode sont une liste d'instruction. Une instruction est constituée de deux informations :
- Le nom de l'instruction
- La valeur associée à l'instruction (si il y en a une)
Ces listes d'instruction est stockée dans des Frames
Classe frame
Une frame est comme une sorte de boite contenant :
- Sa liste d'instruction de bytecode
- Ses variables locales
- Son propre stack d'appel
- Un pointeur d'instruction qui montre la position de l'instruction actuellement executée
- Et un dictionnaire contenant les potentielles variables héritées d'un frame parent (pour la gestion des closures)
Quelques instructions de base en bytecode
Chaque action que fait python a sa propre traduction en bytecode. En voici les instructions de base :
- LOAD_FAST n : Charge la variable locale positionnée à l'indice n, et la push sur la pile d'execution (call stack)
- LOAD_CONST : Push une constante sur la pile
- STORE_FAST : Dépile et stock la valeur dans une variable locale
- BINARY_OP PLUS / MINUS / STAR / SLASH / PERCENT : Dépile les deux derniers elements de la pile, et leur applique l'opération entrée en paramètres :
- PLUS --> Addition
- MINUS --> Soustraction
- STAR --> Multiplication
- SLASH --> Division
- PERCENT --> Modulo
- COMPARE_OP EQEQ / LT / GT / LE / GE / NOTEQ : Opérateurs de comparaison logiques. Dépile les deux derniers elements et les compare :
- EQEQ --> égal (==)
- LT (Lower Than) --> Strictement inférieur (<)
- GT (Greater Than) --> Strictement superieur (>)
- LE (Lower Equal) --> Inférieur ou égal (<=)
- GE (Greater Equal) --> Supperieur ou égal (>=)
- NOTEQ (NOT Equal) --> Différent de (!=)
- POP_JUMP_IF_FALSE n / POP_JUMP_IF_TRUE : Dépile, et effectue un saut (principe de JUMP comme en assembleur) à l'instruction à l'indice n de la liste si la valeur qu'il vient de dépiler est vraie (TRUE) ou fausse (FALSE).
- JUMP_ABSOLUTE n : Effectue un saut à l'instruction d'indice n
- STORE_NAME name : Dépile et crée une variable 'name' dans laquelle il stocke cette valeur
- LOAD_NAME name : Charge ce qui est stocké au nom 'name'
- POP_TOP : Fait un POP sur la pile (c'est à dire dépile)